AI Lead Qualification for Mortgage Lender
#Fintech #AIEngeneering #LeadQualification
Project definition
Location
Client
Project type
Industry
Service list
Back-end Development
AI Engineering
DevOps
Service Integration
Team size
M-Size (4–8 engineers)
Budget
$50,000 – $250,000
Task
The mortgage lender from Europe approached us with an issue in processing inbound leads: a large backlog of unhandled inquiries was resulting in missed prospects and, consequently, financial and reputational losses. The primary objective was to automate the first contact and qualification stages to reduce time‑to‑response and prevent lead leakage
Solution
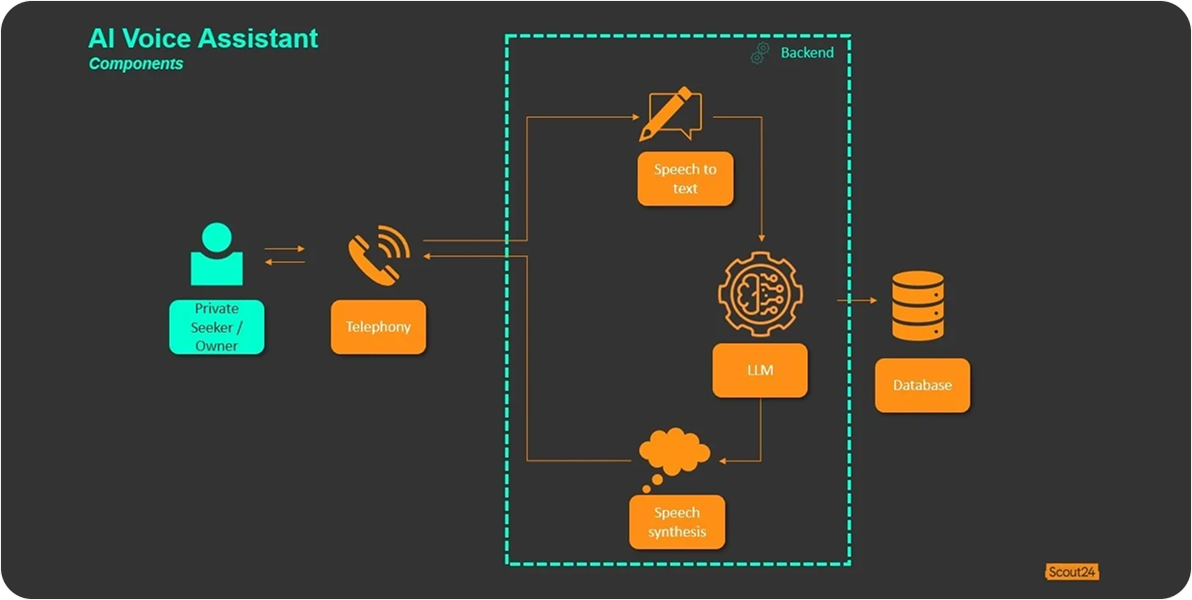
To resolve a large backlog problem our company built an AI voice assistant that answers/handles incoming calls, asks a fixed set of 10 qualification questions, captures responses via streaming speech‑to‑text, and manages dialog with interruption/resume logic
Impact
Backlog reduction was achieved through automation, leading to faster processing of incoming requests. First response times improved significantly, enabling quicker engagement with customers. Qualification calls became shorter and more efficient, saving time for both agents and customers. Data accuracy increased due to structured data capture methods integrated into the system. Operational costs were lowered through automation, improving overall service efficiency. Numeric KPIs reflecting these improvements are confidential and under NDA





💡 This is an AI-CORE project
💡 This is an AI-powered project
💡 Have a similar Industrial or Energy request?
💡 Have a similar Healthcare request?
💡 Have a similar EdTech request?
💡 Have a similar FinTech request?
💡 Have a similar request?
Fixed Qualification Questions
The AI voice assistant uses a set of 10 fixed qualification questions to standardize lead evaluation
Advanced Call-Flow Control
Incorporates interruption and resume logic to handle real-time conversation efficiently
Real-Time Streaming Audio
Utilizes WebRTC streaming audio for high-quality, uninterrupted voice communication
Intelligent Multi-Agent Orchestration
Employs multi-agent large language models to manage dialogue and provide accurate responses
Significant Operational Improvements
Resulted in backlog reduction, faster lead responses, shorter qualification calls, higher data accuracy, and lower operational costs through automation
Development Process
Our team designed the overall system architecture and developed a state machine to handle call flows. The backend, built in Python with asyncio, managed the core call-assistant logic and orchestrated integrations with WebRTC to enable real-time audio streaming, AWS Transcribe for chunked speech-to-text processing, and a TTS engine for dynamic responses. To minimize latency, the system leveraged a multi-agent LLM setup, while Twilio Voice API was used during the proof-of-concept stage. All components were containerized with Docker to ensure scalability and ease of deployment. On the frontend, we delivered a lightweight HTML/CSS/JavaScript interface for call control. Additionally, we introduced observability with latency tracing, alongside load and stress testing, to validate and iteratively optimize system performance
Technologies
AI Lead Qualification for Mortgage Lender
AI-driven voice assistant that qualifies inbound mortgage leads
Book a call with our Head of Sales


